Wielkość próby a normalność rozkładu. Czy test Shapiro-Wilka może wprowadzać w błąd?
W statystyce medycznej często zakłada się, że test normalności (najczęściej Shapiro-Wilka) daje jednoznaczną odpowiedź: rozkład jest…
Czytaj więcej >W statystyce medycznej często zakłada się, że test normalności (najczęściej Shapiro-Wilka) daje jednoznaczną odpowiedź: rozkład jest normalny albo nie. W praktyce analiza danych statystycznych powinna wyglądać inaczej. A to dlatego, że wynik testu na normalność rozkładu bardzo silnie zależy od liczebności próby. Dlaczego tak się dzieje? Wyjaśniam poniżej na przykładach.
Weźmy następujący zbiór danych:
7, 7, 1, 5, 9, 8, 7, 5, 8, 6
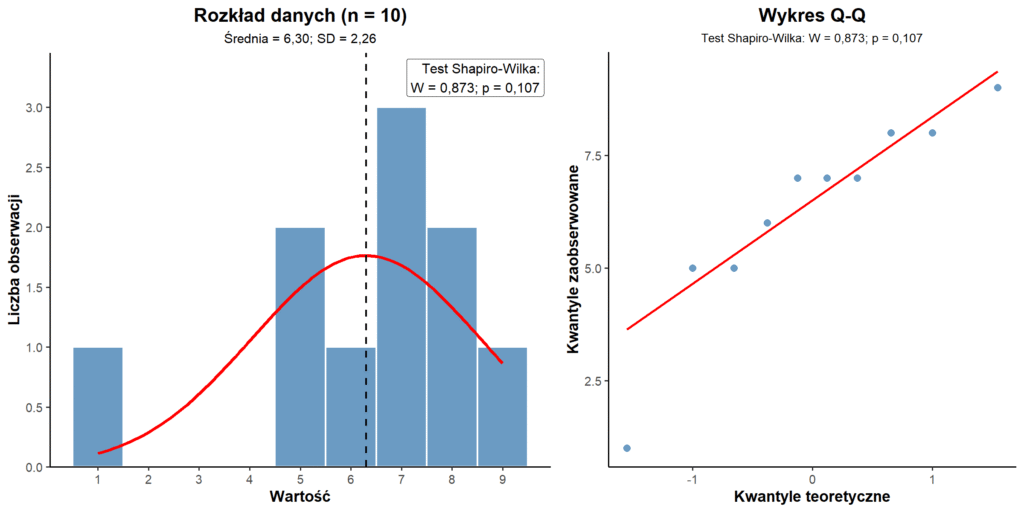
Dla tego zbioru liczb test Shapiro-Wilka daje nam wartość p = 0,107, a ta sugeruje brak podstaw do odrzucenia normalności rozkładu. Ze statystycznego na język polski oznacza to, że uznajemy, iż rozkład jest normalny. Ale czy to jednocześnie oznacza, że możemy zastosować test parametryczny? Sprawdźmy to!
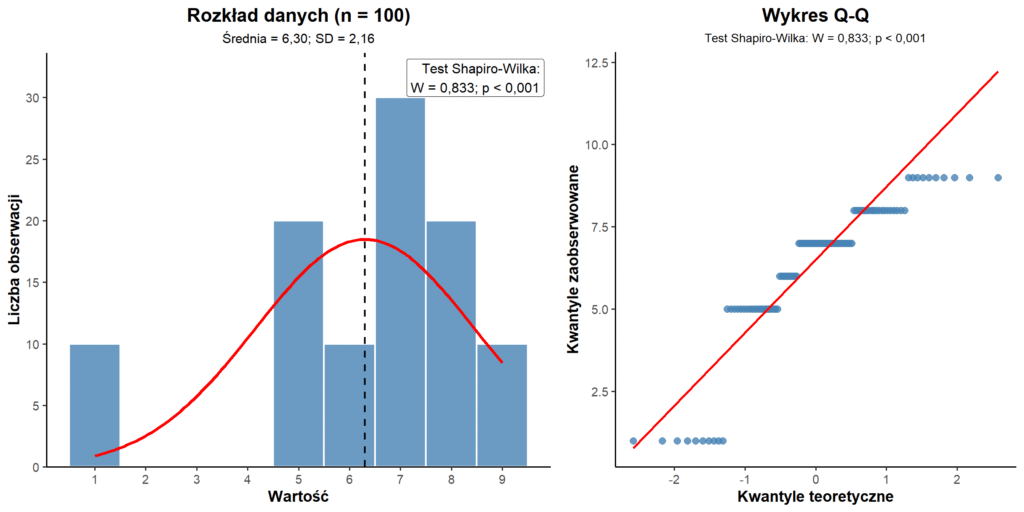
Powielmy dokładnie ten sam zestaw 10x, czyli otrzymamy zbiór o liczebności n = 100. Na wykresie otrzymujemy identyczny „kształt” danych, mamy tylko większą próbę.
Następnie wykonujemy ponownie test Shapiro-Wilka, który dla tej samej struktury danych co w poprzednim przykładzie, ale innej liczebności, daje nam tym razem wartość p < 0,00000001. Taka wartość p daje mocną podstawę do stwierdzenia braku rozkładu normalnego. I znów ze statystycznego na polski: rozkład nie jest normalny. Czyli tym razem musimy zastosować test nieparametryczny?
Rozkład danych się przecież zupełnie nie zmienił (liczby są te same, ale jest ich 10x więcej). Zmieniła się tylko liczebność próby, a mimo to wniosek statystyczny jest zupełnie inny. O co w tym chodzi?
Test Shapiro-Wilka nie odpowiada na pytanie: czy dane są „wystarczająco normalne”? On odpowiada na pytanie: czy dane są idealnie zgodne z rozkładem normalnym. Ta subtelna różnica potrafi wywrócić całą analizę normalności rozkładu i wnioskowanie!
Dla n = 10 mamy w teście Shapiro-Wilka p = 0,107, czyli bazując tylko na tej wartości p uznajemy rozkład za normalny. Histogram poniżej pokazuje jednak, że rozkład jest nieregularny, ale test Shapiro-Wilka tego „nie widzi”.
Dla n = 100 mamy w teście Shapiro-Wilka p < 0,001, czyli bazując tylko na tej wartości p uznajemy rozkład za niezgodny z normalnym. Histogram pokazuje identyczny rozkład jak wcześniej, QQ plot wygląda identycznie strukturalnie, ale test Shapiro-Wilka tym razem „widzi” odchylenie (tylko dlatego, że ma większą moc z uwagi na większą liczbę obserwacji).
W praktyce publikacyjnej bardzo często spotykane jest podejście: „jeśli test Shapiro-Wilka ma p < 0,05 → dane nienormalne → używamy testu nieparametrycznego”.
To oznacza, że wybór testu statystycznego może być nieprawidłowy, jeśli opiera się wyłącznie na teście normalności.
Test normalności powinien być tylko jednym z elementów, a nie decydującym kryterium.